Accelerate large language model decoding with diffusion-model drafters:
draft many tokens in parallel, then verify exactly with the target LLM.
SpecDiff: Jacob K. Christopher · Brian R. Bartoldson · Tal Ben-Nun · Michael Cardei · Bhavya Kailkhura · Ferdinando Fioretto SpecDiff-2: Jameson Sandler · Jacob K. Christopher · Thomas Hartvigsen · Ferdinando Fioretto
This page is intended to be a readable, practitioner-friendly walkthrough. For the authoritative
details (derivations, hyperparameters, and full experiments), see the papers.
Overview
What is speculative diffusion decoding?
Speculative decoding is a draft-then-verify framework: a fast drafter proposes a
short continuation, and a large verifier checks those tokens in parallel. If the draft is
likely under the verifier, you accept a long prefix in one shot.
SpecDiff replaces the autoregressive drafter with a masked discrete diffusion model
that drafts an entire window of tokens in parallel via iterative denoising. This removes a major
bottleneck: drafting no longer requires token-by-token generation.
What does SpecDiff-2 add?
SpecDiff-2 focuses on a core practical issue: drafter–verifier alignment. Diffusion
drafters can be extremely parallel, but if they propose tokens the verifier often rejects, speed-up
evaporates.
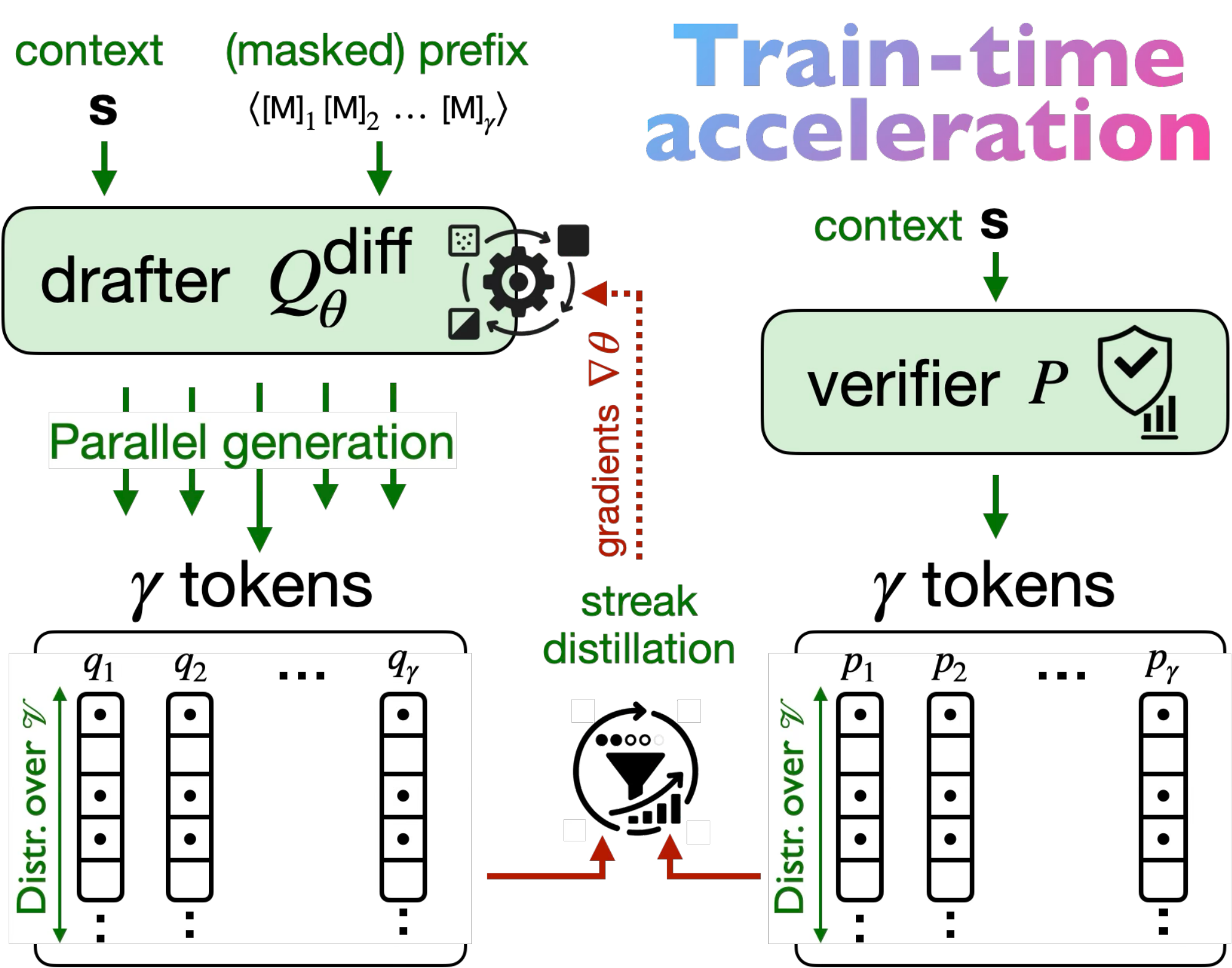
Train-time alignment: streak-distillation to optimize for long accepted prefixes.
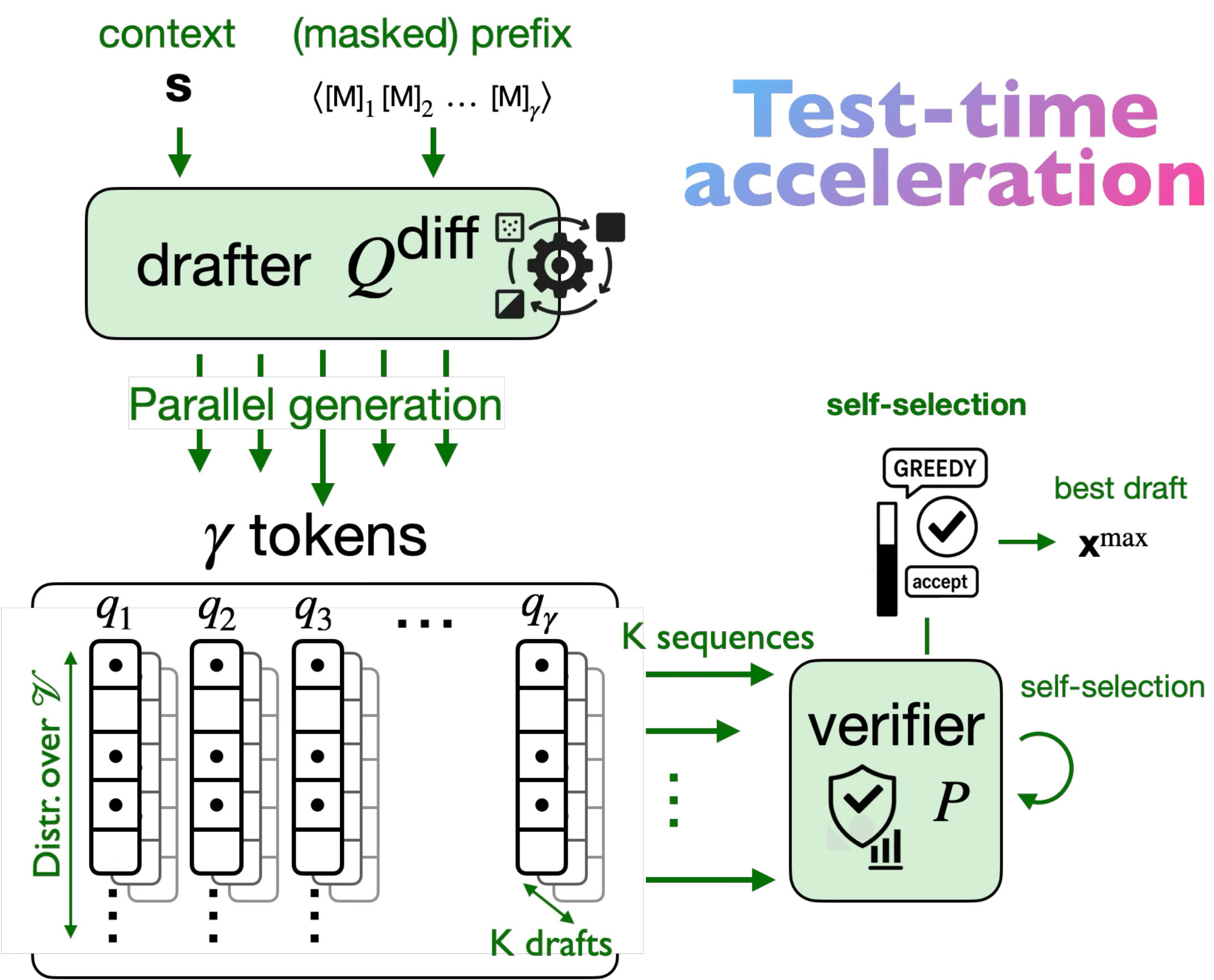
Test-time alignment: self-selection over multiple parallel drafts to maximize expected throughput.
Scaling insight: “acceleration–compute” scaling links faster decoding to better performance under fixed time budgets.
SpecDiff-2 adds two complementary mechanisms on top of diffusion drafting: train-time alignment (streak-distillation) and
test-time selection (self-selection over parallel drafts).
SpecDiff-2 (train-time): streak-distillation trains the diffusion drafter to produce long accepted streaks.SpecDiff-2 (test-time): self-selection picks the draft expected to yield highest throughput.
Papers
SpecDiff
Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion
Introduces diffusion-model drafters for speculative decoding. Shows that masked discrete diffusion
can draft long windows efficiently, enabling parallelism in both drafting and verification.
SpecDiff-2
SpecDiff-2: Scaling Diffusion Drafter Alignment For Faster Speculative Decoding
Adds principled alignment mechanisms tailored to diffusion drafters (streak-distillation + self-selection),
producing stronger end-to-end throughput while preserving lossless verification.
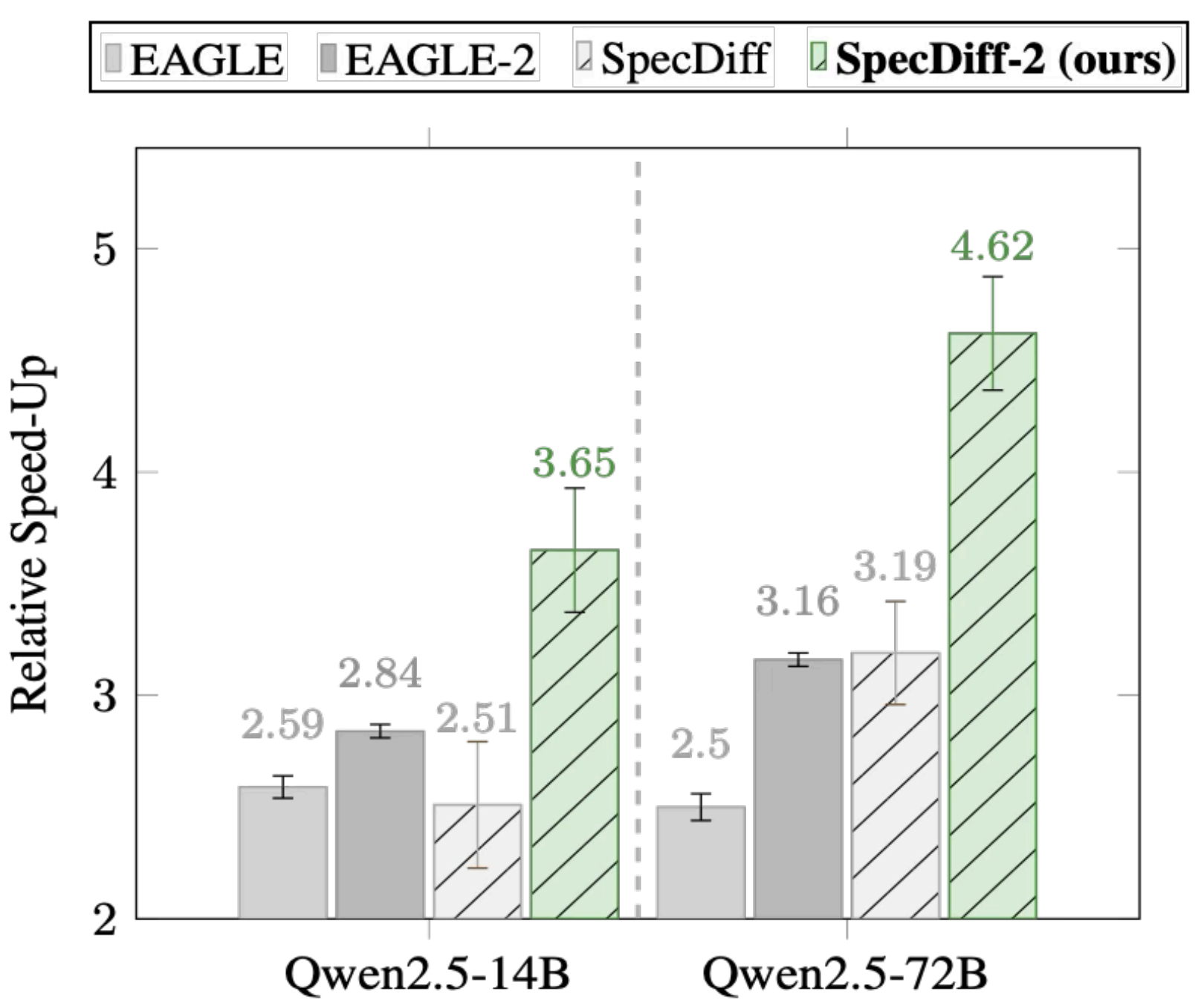
Headline Results (from the papers)
Numbers depend on model/task/settings. The goal here is to capture the “shape” of the gains; please
cite the papers for exact tables and experimental details.
Method
Key idea
Reported speed/throughput highlights
SpecDiff
Masked discrete diffusion drafter
Up to 7.2× vs vanilla decoding; up to 1.75× vs prior speculative baselines (reported).
SpecDiff-2
Alignment + multi-draft self-selection
Average 4.22× speed-ups; up to 5.5×; +55% throughput vs prior baselines (reported).
SpecDiff-2 (time budget)
Acceleration–compute scaling
On a 15s math reasoning budget: +63% accuracy vs vanilla; +11% vs unaligned diffusion drafting (reported).
Blog
Motivation: diffusion drafting removes the sequential drafting bottleneck.
Speculative decoding is a draft-then-verify trick: a cheap drafter proposes multiple next tokens,
and the target model verifies them in parallel. When the draft matches what the verifier would have done,
you “commit” a long prefix in one shot and skip a lot of expensive target-model work.
The catch is that many speculative systems still use an autoregressive drafter. Even if verification is
parallel, drafting remains sequential — and that sequential drafting becomes the bottleneck as you scale draft length.
SpecDiff’s central move is to replace that sequential drafter with a masked discrete diffusion model
that drafts an entire window in parallel.
Key idea: Use a masked discrete diffusion language model as the drafter so drafting a window of
γ tokens is parallel over positions, with compute controlled primarily by the number of diffusion steps.
What “diffusion drafting” looks like
A masked diffusion LM starts from a window of masked tokens and iteratively denoises them. Each denoising
step produces token distributions for all positions at once, so the draft window is generated “in parallel”
across positions rather than token-by-token.
You can think of it as a text analogue of diffusion for images: the forward process corrupts a clean sequence by masking tokens,
and the reverse process learns to reconstruct the original sequence. At inference, you start from an all-masked window and run a
small number of denoising steps to propose a complete candidate continuation.
High-level SpecDiff loop: draft a window, verify in parallel, accept a prefix, repeat.
Algorithm sketch (high-level)
Each iteration looks like: (1) generate a γ-token draft window with the diffusion drafter
(in T denoising steps), (2) have the target model compute the corresponding probabilities
in parallel, and (3) accept the longest prefix that satisfies the acceptance rule, then continue from the new context.
The important property is that the verifier still defines the distribution: acceptance/rejection is designed so the final output
matches the target model’s decoding distribution, while reducing the number of verifier steps needed to produce the same number of tokens.
Why γ can be larger for diffusion drafters
Because drafting is parallel over positions, the cost of increasing the draft length is much smaller than it is for
autoregressive drafters. In practice, SpecDiff’s performance becomes more sensitive to the number of denoising steps than
to γ itself, which opens the door to longer windows without paying a proportional cost.
A recurring theme (and the focus of SpecDiff-2): speed-ups come from both parallelism and alignment. If later draft
tokens are often rejected, effective throughput drops.
SpecDiff-2 treats the core practical issue head-on: drafter–verifier alignment.
Even if diffusion drafting is highly parallel, the system only speeds up when the verifier accepts long prefixes.
When acceptance is low — especially later in the draft window — you spend compute on tokens that never get committed.
SpecDiff-2 in one line: keep diffusion drafting, but align the drafter to maximize the length of accepted
streaks (train-time), and pick the best among multiple candidate drafts (test-time).
Two bottlenecks SpecDiff-2 targets
First, classic speculative decoding often uses an autoregressive drafter, which introduces sequential dependency during drafting.
Second, even with a non-autoregressive drafter, misalignment between drafter and verifier causes frequent rejections,
collapsing the realized speed-up.
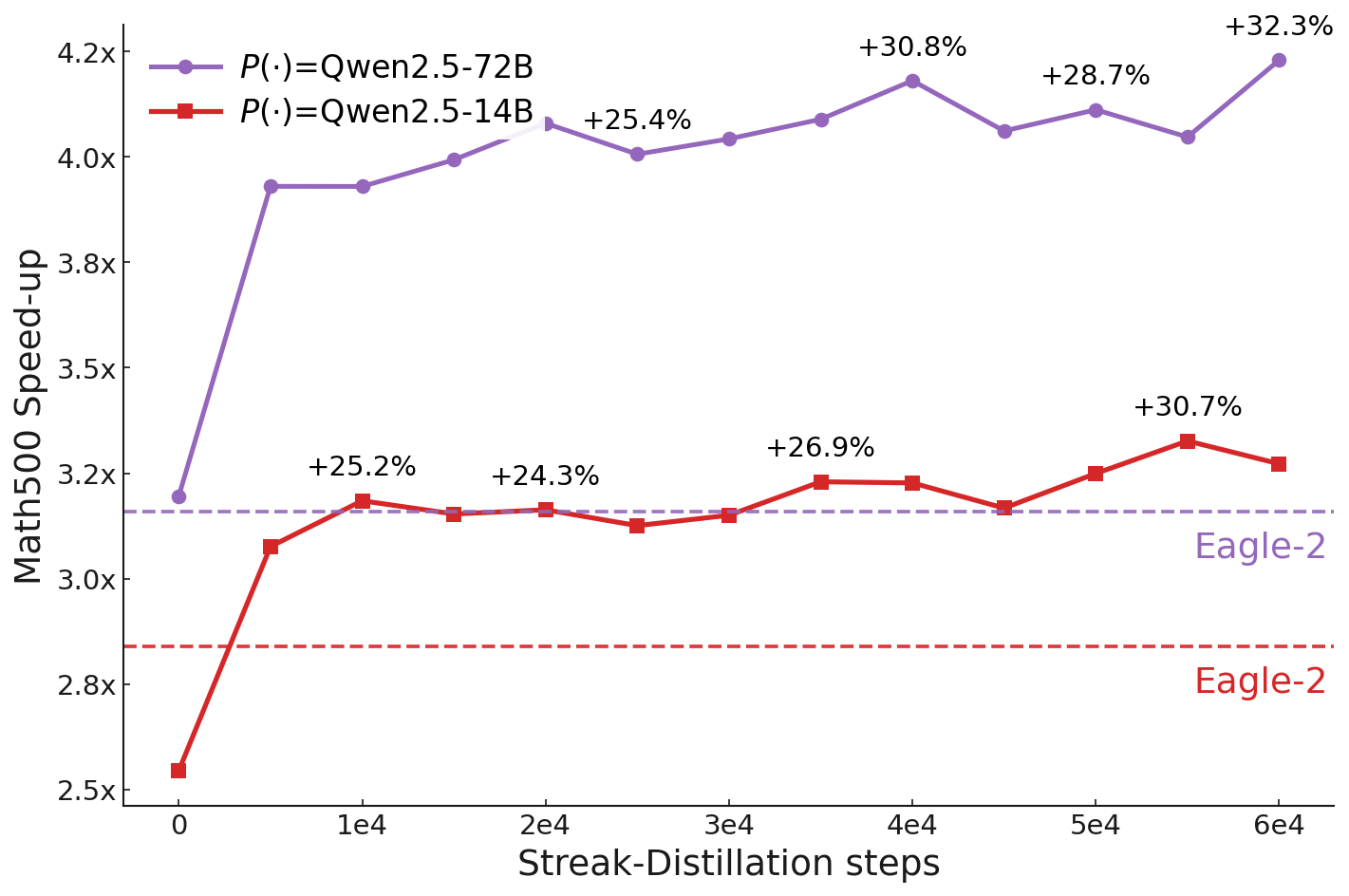
Train-time acceleration: streak-distillation
Rather than optimizing token-wise match, streak-distillation optimizes for contiguous accepted prefixes.
The intuition is simple: verification commits a prefix, not independent tokens, so the objective should directly reward
long accepted runs (“streaks”).
Streak-distillation training improves Math500 speed-up over time (reported).
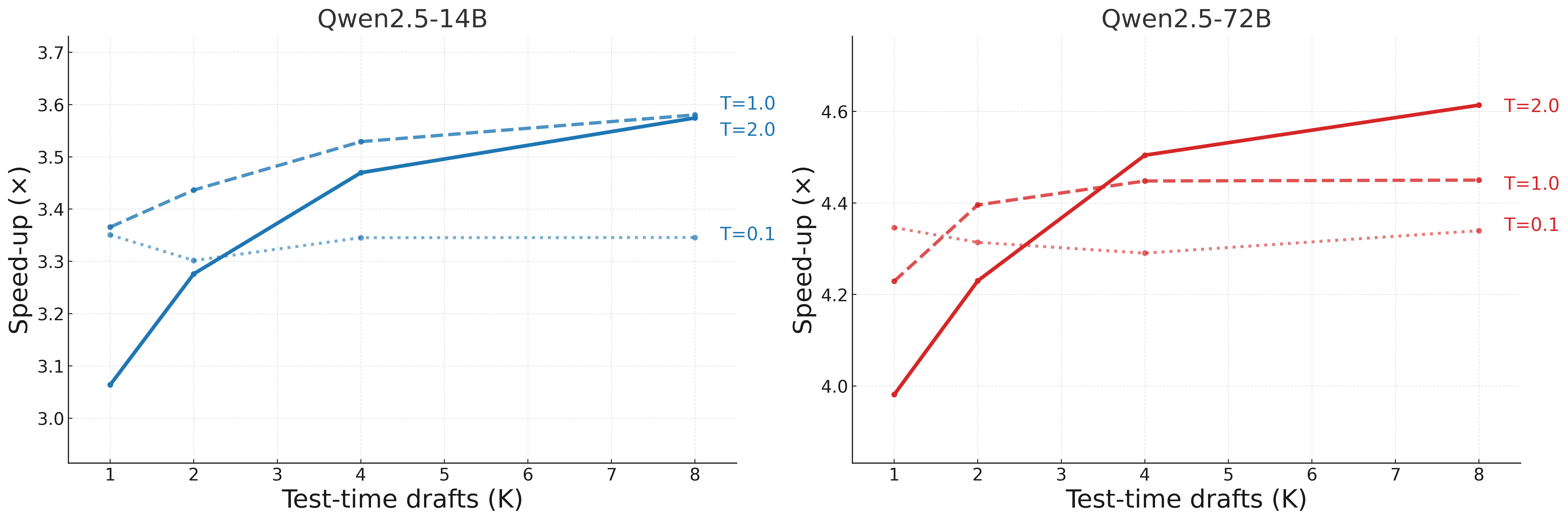
Test-time acceleration: self-selection
At inference time, diffusion models make it cheap to sample multiple candidate drafts in parallel.
SpecDiff-2 uses this to generate K drafts, estimate their expected throughput under the verifier,
and verify only the best candidate.
Intuitively, you want the draft that is most likely to yield a long accepted prefix. Self-selection turns that into a lightweight
search over parallel candidates — leveraging the fact that diffusion drafters can produce many joint samples from essentially the same
underlying position-wise predictions.
Self-selection: generate multiple drafts and verify the one expected to yield the best throughput.
Acceleration–compute scaling
A key takeaway is that faster decoding can translate into better results under time constraints.
If you can generate more tokens in the same wall-clock budget, you can allocate more “thinking” to reasoning-heavy tasks
(e.g., longer reasoning traces or more attempts).
Faster decoding → higher accuracy under fixed budgets (reported on Math500 with a 15s budget).
BibTeX
SpecDiff
@inproceedings{christopher2025specdiff,
title = {Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion},
author = {Christopher, Jacob K. and Bartoldson, Brian R. and Ben-Nun, Tal and Cardei, Michael and Kailkhura, Bhavya and Fioretto, Ferdinando},
booktitle = {Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies},
year = {2025},
url = {https://aclanthology.org/2025.naacl-long.601/}
}
SpecDiff-2
@inproceedings{sandler2026specdiff2,
title = {SpecDiff-2: Scaling Diffusion Drafter Alignment For Faster Speculative Decoding},
author = {Sandler, Jameson and Christopher, Jacob K. and Hartvigsen, Thomas and Fioretto, Ferdinando},
booktitle = {Proceedings of Machine Learning and Systems (MLSys)},
year = {2026},
url = {https://mlsys.org/},
note = {Accepted to MLSys; arXiv:2511.00606}
}